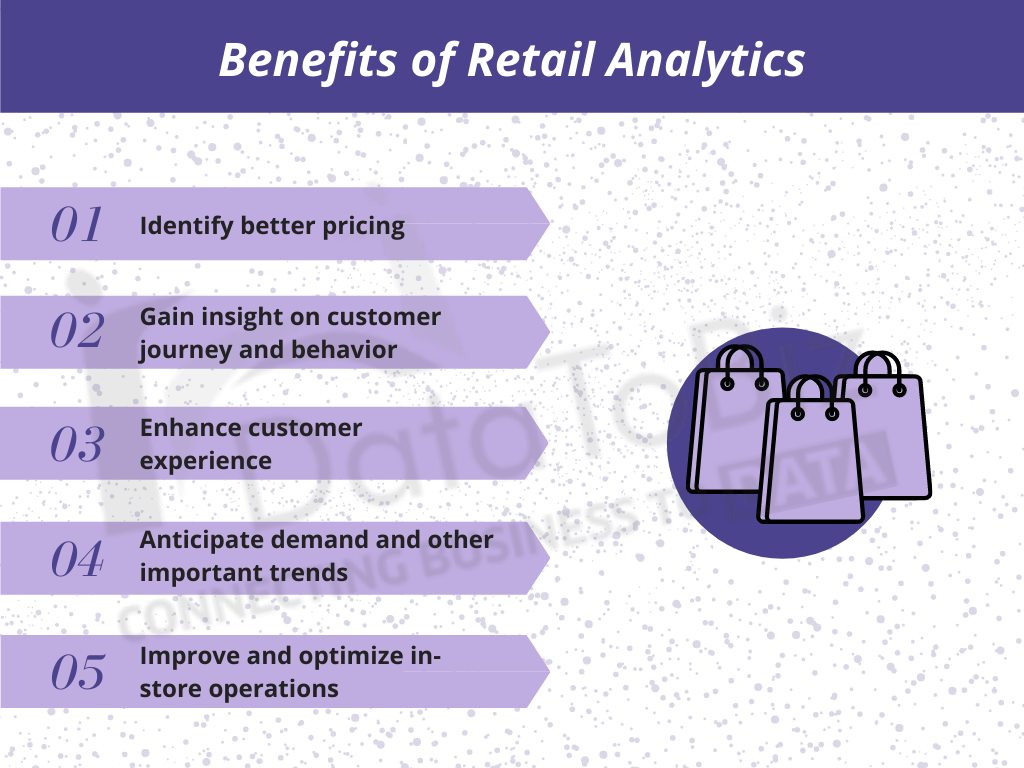
Data Scuffing Vs Information Creeping: The Distinctions So you first crawl - or find - the Links, download and install the html files and then scratch the information from those files. Which means you draw out data and do something with it, like store it in a data http://arthurzwkr735.timeforchangecounselling.com/web-scuffing-for-the-traveling-industry-usecases-and-automation-concepts source or further procedure it. It is very important to the success of your organization that you use the most effective online crawling tools available today. In this manner, you don't need to throw away long hours that cause a badly done task that consists of encountering lawful troubles. Simply put, web scuffing is information removal from an internet site, while internet crawling is the exploration of target Links. Web crawling is a certain sort of data creeping that entails immediately drawing out information from websites. File style, Microsoft Excel is maybe the most extensively utilized information scraping kind made use of in the work environment and for office presentations. We live in a modern-day globe of electronic technology and all of the globe's info is conveniently available on the web.
AI chatbots compared: Bard vs. Bing vs. ChatGPT - The Verge
AI chatbots compared: Bard vs. Bing vs. ChatGPT.
Posted: Fri, 24 Mar 2023 07:00:00 GMT [source]
The Tools
Data scratching needs a parser and scrape agent, and data crawling needs just one crawler crawler. Information scuffing is done on little and large scales, while information creeping is generally done on a large scale. Information scratching doesn't involve checking out all target web pages to download data, while internet crawling calls for seeing each website up until the URL frontier is empty. The grey area can be found in with just how you are using the information and whether or not you have approval to access the data on particular sites. When thinking about utilizing internet crawling and internet scuffing with each other, you can develop an entirely automated process. You can produce a list of web links through API calls and save them in a style that your web scraper can make use of to extract data from those certain web pages. Once you have a system like this in place, you can obtain information from throughout the web without needing to do much manual labor.- This will certainly offer you much more control over what data you extract from websites, but it can take a substantial quantity of time.Globe creating 1.145 trillion MB of information daily, humans can't evaluate and structure it alone.Both scraping and crawling work together in the entire process of data celebration, so normally, when one is done, the other follows.